Algoritmo del banquero

El Algoritmo del banquero, en sistemas operativos es una forma de evitar el interbloqueo, propuesta por primera vez por Edsger Dijkstra. Es un acercamiento teórico para evitar los interbloqueos en la planificación de recursos. Requiere conocer con anticipación los recursos que serán utilizados por todos los procesos. Esto último generalmente no puede ser satisfecho en la práctica.
Este algoritmo usualmente es explicado usando la analogía con el funcionamiento de un banco. Los clientes representan a los procesos, que tienen un crédito límite, y el dinero representa a los recursos. El banquero es el sistema operativo.
El banco confía en que no tendrá que permitir a todos sus clientes la utilización de todo su crédito a la vez. El banco también asume que si un cliente maximiza su crédito será capaz de terminar sus negocios y devolver el dinero a la entidad, permitiendo servir a otros clientes.

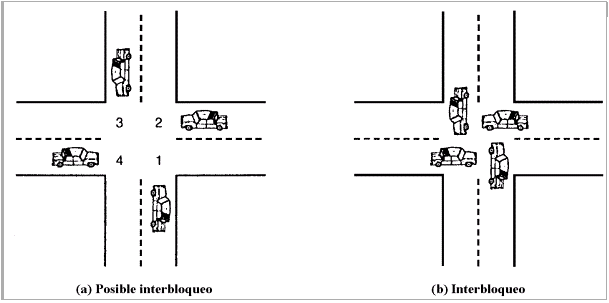
El algoritmo mantiene al sistema en un estado seguro. Un sistema se encuentra en un estado seguro si existe un orden en que pueden concederse las peticiones de recursos a todos los procesos, previniendo el interbloqueo. El algoritmo del banquero funciona encontrando estados de este tipo.
Los procesos piden recursos, y son complacidos siempre y cuando el sistema se mantenga en un estado seguro después de la concesión. De lo contrario, el proceso es suspendido hasta que otro proceso libere recursos suficientes.
En términos más formales, un sistema se encuentra en un estado seguro si existe una secuencia segura. Una secuencia segura es una sucesión de procesos, 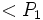 ,...,
,..., 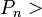 , donde para un proceso
, donde para un proceso 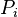 , el pedido de recursos puede ser satisfecho con los recursos disponibles sumados los recursos que están siendo utilizados por
, el pedido de recursos puede ser satisfecho con los recursos disponibles sumados los recursos que están siendo utilizados por 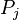 , donde j < i. Si no hay suficientes recursos para el proceso , debe esperar hasta que algún proceso termine su ejecución y libere sus recursos. Recién entonces podrá tomar los recursos necesarios, utilizarlos y terminar su ejecución. Al suceder esto, el proceso
, donde j < i. Si no hay suficientes recursos para el proceso , debe esperar hasta que algún proceso termine su ejecución y libere sus recursos. Recién entonces podrá tomar los recursos necesarios, utilizarlos y terminar su ejecución. Al suceder esto, el proceso  i+1 puede tomar los recursos que necesite, y así sucesivamente. Si una secuencia de este tipo no existe, el sistema se dice que está en un estado inseguro, aunque esto no implica que esté bloqueado.
i+1 puede tomar los recursos que necesite, y así sucesivamente. Si una secuencia de este tipo no existe, el sistema se dice que está en un estado inseguro, aunque esto no implica que esté bloqueado.
,..., , donde para un proceso , el pedido de recursos puede ser satisfecho con los recursos disponibles sumados los recursos que están siendo utilizados por , donde j < i. Si no hay suficientes recursos para el proceso , debe esperar hasta que algún proceso termine su ejecución y libere sus recursos. Recién entonces podrá tomar los recursos necesarios, utilizarlos y terminar su ejecución. Al suceder esto, el proceso i+1 puede tomar los recursos que necesite, y así sucesivamente. Si una secuencia de este tipo no existe, el sistema se dice que está en un estado inseguro, aunque esto no implica que esté bloqueado.
Así, el uso de este tipo de algoritmo permite impedir el interbloqueo, pero supone una serie de restricciones:
Se debe conocer la máxima demanda de recursos por anticipado.
Los procesos deben ser independientes, es decir que puedan ser ejecutados en cualquier orden. Por lo tanto su ejecución no debe estar forzada por condiciones de sincronización.
Debe haber un número fijo de recursos a utilizar y un número fijo de procesos.
Los procesos no pueden finalizar mientras retengan recursos.



 Pipelining
Pipelining